pytorch入门8 |
您所在的位置:网站首页 › cpu gpu都不满载 › pytorch入门8 |
pytorch入门8
|
一、读写文件 有时我们希望保存训练的模型, 以备将来在各种环境中使用(比如在部署中进行预测)。 此外,当运行一个耗时较长的训练过程时, 最佳的做法是定期保存中间结果, 以确保在服务器电源被不小心断掉时,我们不会损失几天的计算结果。 因此,现在是时候学习如何加载和存储权重向量和整个模型了。 1.加载和保存张量 对于单个张量,我们可以直接调用load和save函数分别读写它们。 这两个函数都要求我们提供一个名称,save要求将要保存的变量作为输入。save()第二个参数是文件的存储路径。 (1)保存 二、GPU 我们将讨论如何利用这种计算性能进行研究。 首先是如何使用单个GPU,然后是如何使用多个GPU和多个服务器(具有多个GPU)。 在PyTorch中,每个数组都有一个设备(device), 我们通常将其称为环境(context)。 默认情况下,所有变量和相关的计算都分配给CPU。 有时环境可能是GPU。 当我们跨多个服务器部署作业时,事情会变得更加棘手。 通过智能地将数组分配给环境, 我们可以最大限度地减少在设备之间传输数据的时间。 例如,当在带有GPU的服务器上训练神经网络时, 我们通常希望模型的参数在GPU上。 默认情况下,张量是在内存中创建的,然后使用CPU计算它。 在PyTorch中,CPU和GPU可以用torch.device(‘cpu’) 和torch.device(‘cuda’)表示。 应该注意的是,cpu设备意味着所有物理CPU和内存, 这意味着PyTorch的计算将尝试使用所有CPU核心。 然而,gpu设备只代表一个卡和相应的显存。 如果有多个GPU,我们使用torch.device(f’cuda:{i}') 来表示第i块GPU(i从0开始)。 另外,cuda:0和cuda是等价的。 import torch from torch import nn torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1')我们可以查询可用gpu的数量: torch.cuda.device_count()我们可以查询张量所在的设备。 默认情况下,张量是在CPU上创建的。
当输入为GPU上的张量时,模型将在同一GPU上计算结果。 |
 运行后可以发现在运行代码的文件的当前目录和上一层目录分别有一个x-file文件。 2.加载
运行后可以发现在运行代码的文件的当前目录和上一层目录分别有一个x-file文件。 2.加载  我们可以存储一个张量列表,然后把它们读回内存。
我们可以存储一个张量列表,然后把它们读回内存。 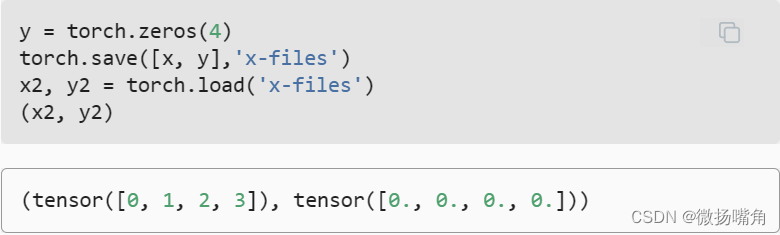 我们甚至可以写入或读取从字符串映射到张量的字典。 当我们要读取或写入模型中的所有权重时,这很方便。
我们甚至可以写入或读取从字符串映射到张量的字典。 当我们要读取或写入模型中的所有权重时,这很方便。 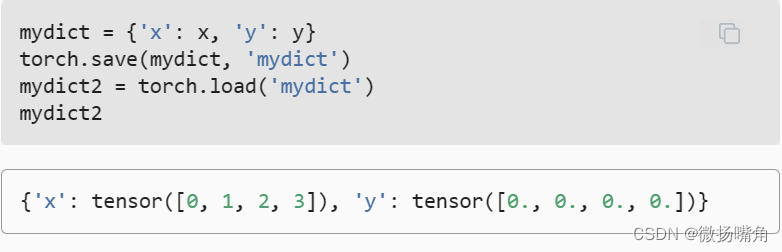 2.加载和保存模型参数 保存单个权重向量(或其他张量)确实有用, 但是如果我们想保存整个模型,并在以后加载它们, 单独保存每个向量则会变得很麻烦。 毕竟,我们可能有数百个参数散布在各处。 因此,深度学习框架提供了内置函数来保存和加载整个网络。 需要注意的一个重要细节是,这将保存模型的参数而不是保存整个模型。 例如,如果我们有一个3层多层感知机,我们需要单独指定架构。 因为模型本身可以包含任意代码,所以模型本身难以序列化。 因此,为了恢复模型,我们需要用代码生成架构, 然后从磁盘加载参数。 让我们从熟悉的多层感知机开始尝试一下。
2.加载和保存模型参数 保存单个权重向量(或其他张量)确实有用, 但是如果我们想保存整个模型,并在以后加载它们, 单独保存每个向量则会变得很麻烦。 毕竟,我们可能有数百个参数散布在各处。 因此,深度学习框架提供了内置函数来保存和加载整个网络。 需要注意的一个重要细节是,这将保存模型的参数而不是保存整个模型。 例如,如果我们有一个3层多层感知机,我们需要单独指定架构。 因为模型本身可以包含任意代码,所以模型本身难以序列化。 因此,为了恢复模型,我们需要用代码生成架构, 然后从磁盘加载参数。 让我们从熟悉的多层感知机开始尝试一下。  接下来,我们将模型的参数存储在一个叫做“mlp.params”的文件中。
接下来,我们将模型的参数存储在一个叫做“mlp.params”的文件中。  为了恢复模型,我们实例化了原始多层感知机模型的一个备份。 这里我们不需要随机初始化模型参数,而是直接读取文件中存储的参数。
为了恢复模型,我们实例化了原始多层感知机模型的一个备份。 这里我们不需要随机初始化模型参数,而是直接读取文件中存储的参数。 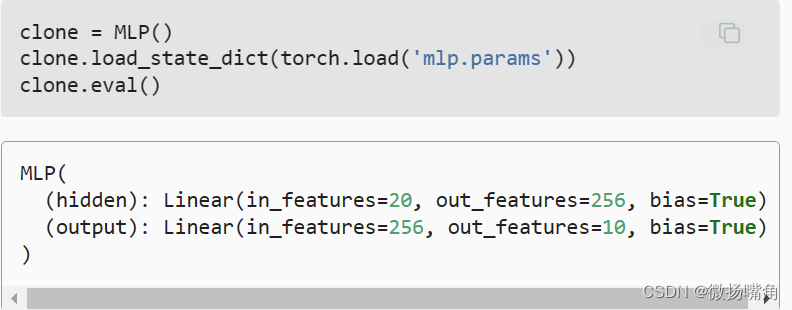 由于两个实例具有相同的模型参数,在输入相同的X时, 两个实例的计算结果应该相同。 让我们来验证一下。
由于两个实例具有相同的模型参数,在输入相同的X时, 两个实例的计算结果应该相同。 让我们来验证一下。 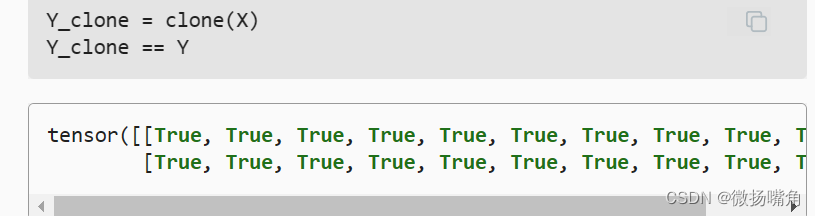
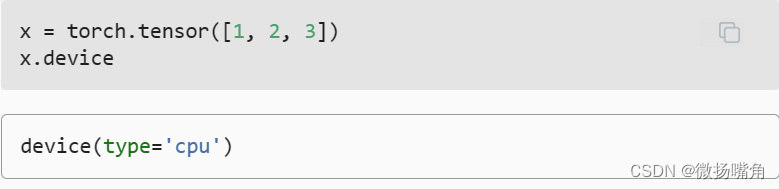 需要注意的是,无论何时我们要对多个项进行操作, 它们都必须在同一个设备上。 例如,如果我们对两个张量求和, 我们需要确保两个张量都位于同一个设备上, 否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算。 存储在GPU上: 有几种方法可以在GPU上存储张量。 例如,我们可以在创建张量时指定存储设备。接 下来,我们在第一个gpu上创建张量变量X。 在GPU上创建的张量只消耗这个GPU的显存。 我们可以使用nvidia-smi命令查看显存使用情况。 一般来说,我们需要确保不创建超过GPU显存限制的数据。
需要注意的是,无论何时我们要对多个项进行操作, 它们都必须在同一个设备上。 例如,如果我们对两个张量求和, 我们需要确保两个张量都位于同一个设备上, 否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算。 存储在GPU上: 有几种方法可以在GPU上存储张量。 例如,我们可以在创建张量时指定存储设备。接 下来,我们在第一个gpu上创建张量变量X。 在GPU上创建的张量只消耗这个GPU的显存。 我们可以使用nvidia-smi命令查看显存使用情况。 一般来说,我们需要确保不创建超过GPU显存限制的数据。 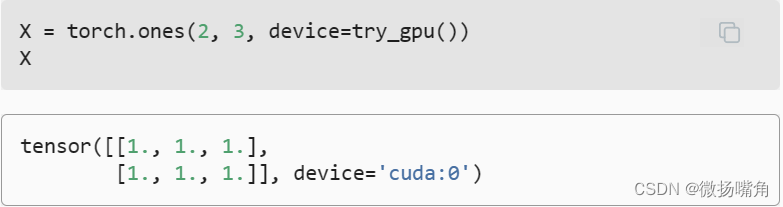 假设我们至少有两个GPU,下面的代码将在第二个GPU上创建一个随机张量:
假设我们至少有两个GPU,下面的代码将在第二个GPU上创建一个随机张量: 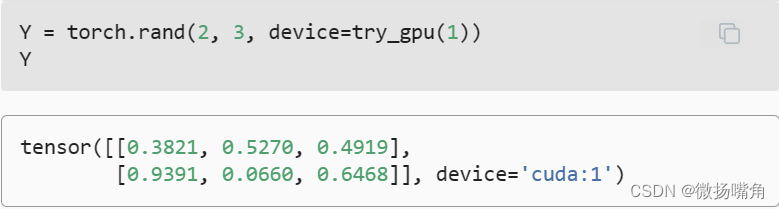 复制: 如果我们要计算X + Y,我们需要决定在哪里执行这个操作。 例如,如 图5.6.1所示, 我们可以将X传输到第二个GPU并在那里执行操作。 不要简单地X加上Y,因为这会导致异常, 运行时引擎不知道该怎么做:它在同一设备上找不到数据会导致失败。 由于Y位于第二个GPU上,所以我们需要将X移到那里, 然后才能执行相加运算。
复制: 如果我们要计算X + Y,我们需要决定在哪里执行这个操作。 例如,如 图5.6.1所示, 我们可以将X传输到第二个GPU并在那里执行操作。 不要简单地X加上Y,因为这会导致异常, 运行时引擎不知道该怎么做:它在同一设备上找不到数据会导致失败。 由于Y位于第二个GPU上,所以我们需要将X移到那里, 然后才能执行相加运算。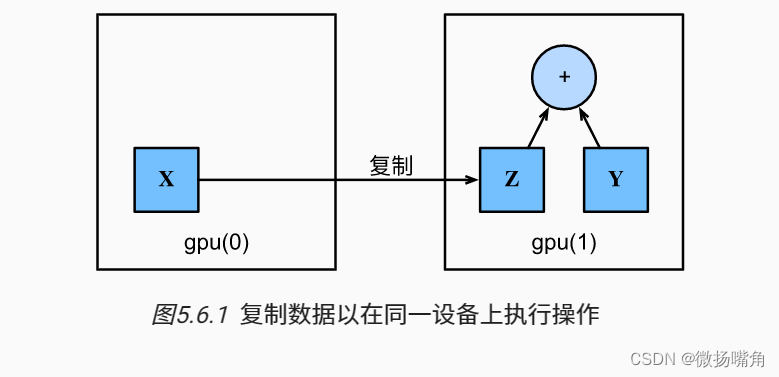
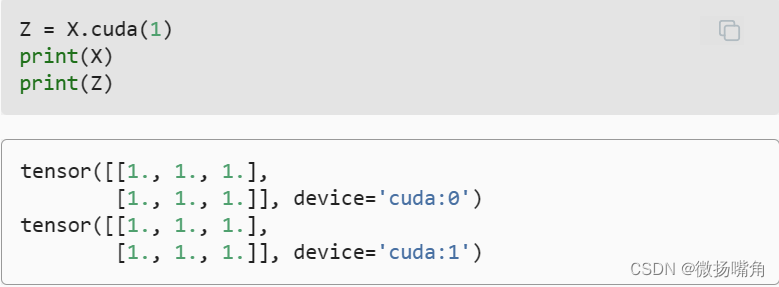 现在数据在同一个GPU上(Z和Y都在),我们可以将它们相加。
现在数据在同一个GPU上(Z和Y都在),我们可以将它们相加。 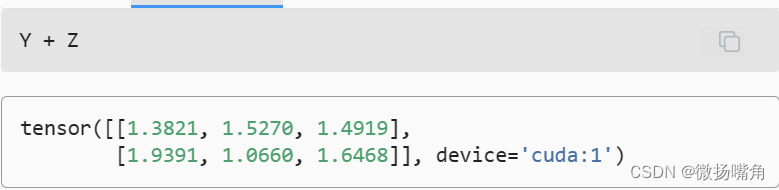 类似地,神经网络模型可以指定设备。 下面的代码将模型参数放在GPU上。
类似地,神经网络模型可以指定设备。 下面的代码将模型参数放在GPU上。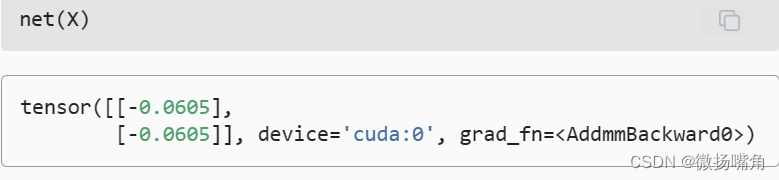 让我们确认模型参数存储在同一个GPU上。
让我们确认模型参数存储在同一个GPU上。  总之,只要所有的数据和参数都在同一个设备上, 我们就可以有效地学习模型。
总之,只要所有的数据和参数都在同一个设备上, 我们就可以有效地学习模型。【本文地址】
今日新闻 |
推荐新闻 |